![]()



よみがな あり|なし
![]()
Saturday,September 10
よみがな自動処理への道【8】1日にして成らず (3 photos)
いくつものヤマを越え、全自動よみがな処理まであともう少し。
いよいよ最後のヤマです。
最後のヤマ「1日にして成らず」
「漢字によみがなをうつ【後編】」 でも取りあげましたが、横書き特有の読み方をするユニークな文字列がいくつかあります。「1日」=「ついたち」「2日」=「ふつか」・・・といった日付の読み方は、MeCabの形態素解析は対応していないのです。
デフォルトの状態でMeCabの辞書には「1日」の2文字で「ついたち」とする読み方は登録されていません。「1日」を形態素解析すると、「1」と「日」に分詞を分けてしまいます。これはプログラム処理において大変具合が悪いんです。
したがって、MeCabの辞書に「1日」といった日付名詞を追加することにします。
Windows7環境でMeCabの辞書に単語登録をする方法
Windows7環境において、MeCabの辞書はデフォルトインストールでは「C:\Program Files \MeCab\dic\ipadic」以下にあるcsvファイル群が相当します。
新規に単語登録する場合は、このディレクトリに適当に名前をつけたcsvファイルをつくって、登録したい単語を記述したうえで辞書のリコンパイルを通せば単語登録できます。
気をつけておきたいことは、Windows用のMeCabのcsv辞書の文字コードはShift-JISで書かれていることです。
作成したcsvファイルを保存するときは文字コードShift-JISで保存することをお忘れなく。
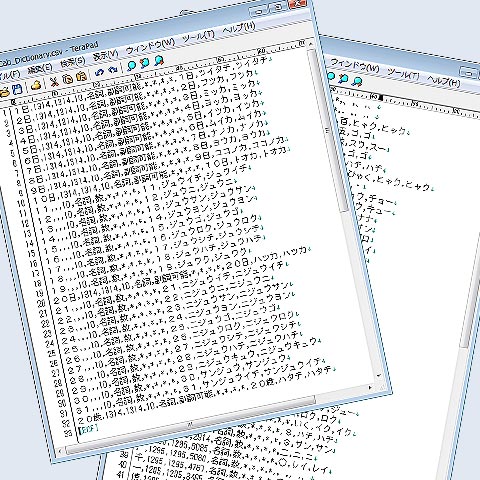
スタジオムーンリーフでは「MeCab_Dictionary.csv」というファイルを作成して、そのファイルに以下のような内容を記述しました。

このファイルを文字コードShift-JISで保存します。
これで終わりかと思いきや、ひとつの罠が。
MeCabにおいて単語登録しただけでは形態素解析の結果に反映されるとは限らないのです。
MeCabは単語の登場頻度を数値化していて、それを文脈からスコア化することで分詞を判定していきます。「1日」といった特殊な文字列の場合、このままでは「1月1日」あるいは「1月1日になりました」といった、前後の分詞のちがいで判定結果が変わってしまうんです。
判定結果が変わってしまう原因は、デフォルトで辞書登録されている数詞「1」~「0」の登場頻度の数値の設定に差があり、それが解析結果に影響しているためです。
数詞については、「C:\Program Files \MeCab\dic\ipadic\Noun.number.csv」に記述されています。登場頻度の数値設定は4カラム目。数値が低いほど登場頻度が高く、数値が高いほど登場頻度が低いことになります。
数詞「1」~「0」の登場頻度は3000台~4000台と千近くの差があり、これがちょうど「1日」とのボーダー上にあるようで、解析結果にバラつきがでてしまうようです。スタジオムーンリーフでは、手作業で数詞「1」~「0」の登場頻度を5000台にまであげました。千の位を5にしただけです。

Noun.number.csvの中身。数詞「1」~「0」の登場頻度を微調整しました
Noun.number.csvも文字コードShift-JISで保存することをお忘れなく。
さて。
最後に辞書のリコンパイルをしてバイナリ辞書にまとめあげれば終了となります。
配布サイトによるとコマンドによるリコンパイルを通す方法もあるようですが、「よみがな自動処理への道【3】Shift-JIS→UTF8へ」で書いたように、好きな文字コードへ辞書のリコンパイルを通したほうが楽でした。

好きな文字コードへ辞書をリコンパイル
コマンドプロンプトで解析結果を確認したいときはShift-JIS。
Perlプログラムで確認したいときはUTF8で辞書をリコンパイルします。
以上で最後のヤマをのぼりきりました。
これでプログラム処理を考えるのが格段にラクになります。
≫ NEXT_LOG よみがな自動処理への道【最終回】まとめ
≪ PREV_LOG よみがな自動処理への道【7】ヤマにも負ケズ

![]()
![]()
![]()
![]()
スタジオムーンリーフ(2005年1月開設/Since 2005)
代表者:野口 卓洋(Takuhiro Noguchi)
Add:356-0006 埼玉県ふじみ野市霞ヶ丘3-1-22-504
Twitter:@StudioMoonLeaf
Facebook:facebook.com/noguchi.takuhiro

©2017 STUDIO MOON LEAF ALL RIGHTS RESERVED.